| 基于中文医药文本的实体识别和图谱构建 |
| |
| 作者姓名: | 杨晔 裴雷 侯凤贞 |
| |
| 作者单位: | 中国药科大学理学院,医药大数据与人工智能研究院,南京 211198,中国药科大学理学院,医药大数据与人工智能研究院,南京 211198,中国药科大学理学院,医药大数据与人工智能研究院,南京 211198 |
| |
| 摘 要: | 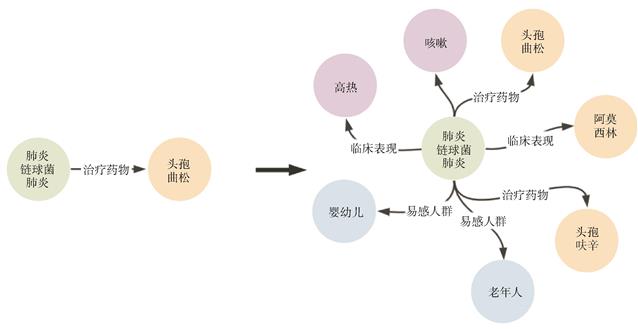
知识图谱技术促进了新药研发的进展,但国内研究起点晚且领域知识多以文本形式存储,图谱重用率低。因此,本研究基于多源异构的医药文本,设计了以Bert-wwm-ext预训练模型为基础,并融合级联思想的中文命名实体识别模型,从而减少了传统单次分类的复杂度,进一步提高了文本识别的效率。实验结果显示,该模型在自建的训练语料上的F1分数达0.903,精确率达89.2%,召回率达91.5%。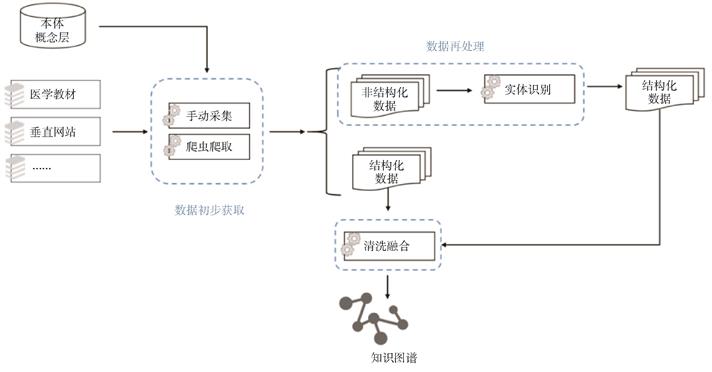
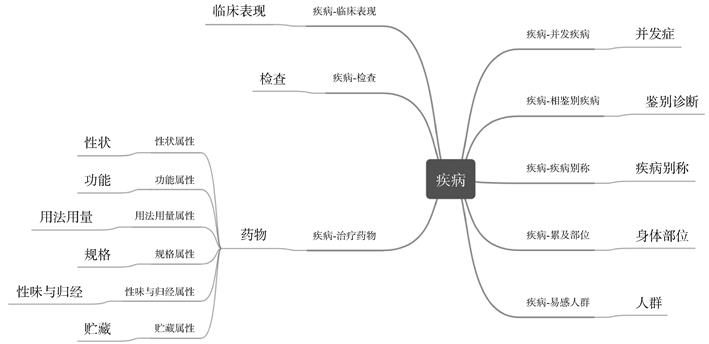
同时,将模型应用于公开数据集CCKS2019上,结果显示该模型能够更好地识别中文文本中的医疗实体。最后,利用此模型构建了一个中文医药知识图谱,图谱包含13 530个实体,10 939个属性,以及39 247个相关关系。本研究所提出的中文医药实体识别与图谱构建方法,有望助力研究者加快医药知识新发现,从而缩短新药研发进程。
|
| 关 键 词: | 中文医药文本 命名实体识别模型 Bert-wwm-ext预训练模型 级联思想 知识图谱 |
| 收稿时间: | 2023-03-09 |
| 修稿时间: | 2023-06-12 |
|
| 点击此处可从《中国药科大学学报》浏览原始摘要信息 |
|
点击此处可从《中国药科大学学报》下载免费的PDF全文 |
|